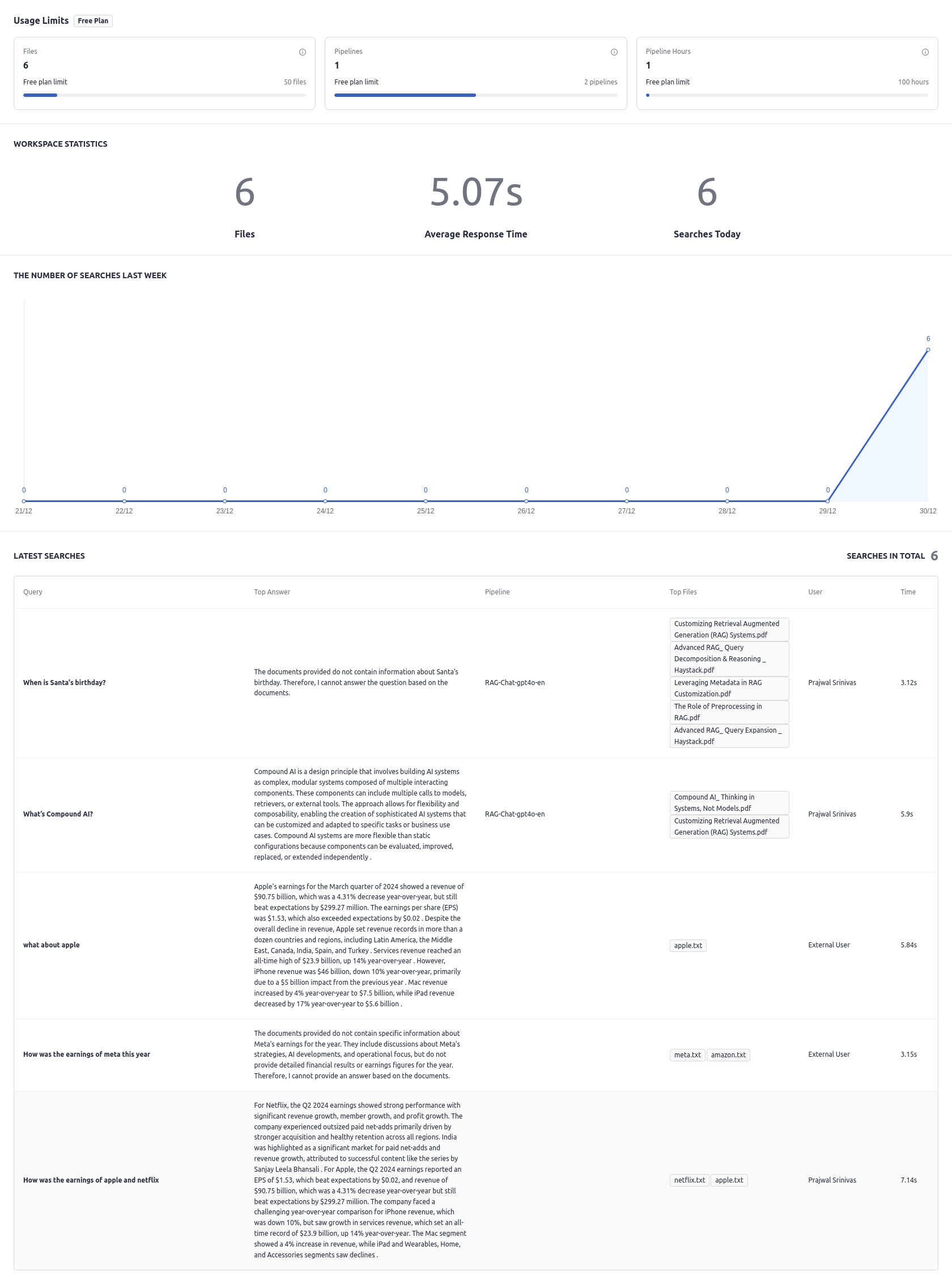
"""# The pipeline contains a component that is only available in deepset Cloud. These components# are optimized to run in a could environment, but you can replace them with the local OSS # version. Check the docs of the component. We provide local examples there. """from haystack import Pipelinefrom haystack.components.routers.file_type_router import FileTypeRouterfrom haystack.components.converters.txt import TextFileToDocumentfrom haystack.components.converters.pypdf import PyPDFToDocumentfrom haystack.components.converters.markdown import MarkdownToDocumentfrom haystack.components.converters.html import HTMLToDocumentfrom haystack.components.converters.docx import DOCXToDocumentfrom haystack.components.converters.pptx import PPTXToDocumentfrom deepset_cloud_custom_nodes.converters.xlsx import XLSXToDocumentfrom haystack.components.converters.csv import CSVToDocumentfrom haystack.components.joiners.document_joiner import DocumentJoinerfrom haystack.components.preprocessors.nltk_document_splitter import NLTKDocumentSplitterfrom deepset_cloud_custom_nodes.embedders.nvidia.document_embedder import DeepsetNvidiaDocumentEmbedderfrom haystack_integrations.document_stores.opensearch.document_store import OpenSearchDocumentStorefrom haystack.components.writers.document_writer import DocumentWriterfile_classifier = FileTypeRouter(mime_types=text/plain,application/pdf,text/markdown,text/html,application/vnd.openxmlformats-officedocument.wordprocessingml.document,application/vnd.openxmlformats-officedocument.presentationml.presentation,application/vnd.openxmlformats-officedocument.spreadsheetml.sheet,text/csv)text_converter = TextFileToDocument(encoding="utf-8")pdf_converter = PyPDFToDocument()markdown_converter = MarkdownToDocument(table_to_single_line=False)html_converter = HTMLToDocument(extraction_kwargs={"output_format": "txt", "target_language": None, "include_tables": True, "include_links": False})docx_converter = DOCXToDocument()pptx_converter = PPTXToDocument()xlsx_converter = XLSXToDocument()csv_converter = CSVToDocument(encoding="utf-8")joiner = DocumentJoiner(join_mode="concatenate", sort_by_score=False)joiner_xlsx = DocumentJoiner(join_mode="concatenate", sort_by_score=False)splitter = NLTKDocumentSplitter(split_by="word", split_length=250, split_overlap=30, respect_sentence_boundary=True, language="en")document_embedder = DeepsetNvidiaDocumentEmbedder(model="intfloat/e5-base-v2", normalize_embeddings=True)document_store = OpenSearchDocumentStore(embedding_dim=768)writer = DocumentWriter(policy="OVERWRITE", document_store=document_store)pipeline = Pipeline()pipeline.add_component("file_classifier", file_classifier)pipeline.add_component("text_converter", text_converter)pipeline.add_component("pdf_converter", pdf_converter)pipeline.add_component("markdown_converter", markdown_converter)pipeline.add_component("html_converter", html_converter)pipeline.add_component("docx_converter", docx_converter)pipeline.add_component("pptx_converter", pptx_converter)pipeline.add_component("xlsx_converter", xlsx_converter)pipeline.add_component("csv_converter", csv_converter)pipeline.add_component("joiner", joiner)pipeline.add_component("joiner_xlsx", joiner_xlsx)pipeline.add_component("splitter", splitter)pipeline.add_component("document_embedder", document_embedder)pipeline.add_component("writer", writer)pipeline.connect("file_classifier.text/plain", "text_converter.sources")pipeline.connect("file_classifier.application/pdf", "pdf_converter.sources")pipeline.connect("file_classifier.text/markdown", "markdown_converter.sources")pipeline.connect("file_classifier.text/html", "html_converter.sources")pipeline.connect("file_classifier.text/csv", "csv_converter.sources")pipeline.connect("text_converter.documents", "joiner.documents")pipeline.connect("pdf_converter.documents", "joiner.documents")pipeline.connect("markdown_converter.documents", "joiner.documents")pipeline.connect("html_converter.documents", "joiner.documents")pipeline.connect("docx_converter.documents", "joiner.documents")pipeline.connect("pptx_converter.documents", "joiner.documents")pipeline.connect("joiner.documents", "splitter.documents")pipeline.connect("splitter.documents", "joiner_xlsx.documents")pipeline.connect("xlsx_converter.documents", "joiner_xlsx.documents")pipeline.connect("csv_converter.documents", "joiner_xlsx.documents")pipeline.connect("joiner_xlsx.documents", "document_embedder.documents")pipeline.connect("document_embedder.documents", "writer.documents")# Documentation:# To run the pipeline, use the pipeline.run() method with the appropriate data.# Here is an example on how to execute the pipeline:# The pipeline is defined and loaded above. To execute it, use:result = pipeline.run(data={"file_classifier":{"sources":"..."}})
# If you need help with the YAML format, have a look at https://docs.cloud.deepset.ai/v2.0/docs/create-a-pipeline#create-a-pipeline-using-pipeline-editor.# This section defines components that you want to use in your pipelines. Each component must have a name and a type. You can also set the component's parameters here.# The name is up to you, you can give your component a friendly name. You then use components' names when specifying the connections in the pipeline.# Type is the class path of the component. You can check the type on the component's documentation page.components:file_classifier:type: haystack.components.routers.file_type_router.FileTypeRouterinit_parameters:mime_types:- text/plain- application/pdf- text/markdown- text/html- application/vnd.openxmlformats-officedocument.wordprocessingml.document- application/vnd.openxmlformats-officedocument.presentationml.presentation- application/vnd.openxmlformats-officedocument.spreadsheetml.sheet- text/csvtext_converter:type: haystack.components.converters.txt.TextFileToDocumentinit_parameters:encoding: utf-8pdf_converter:type: haystack.components.converters.pypdf.PyPDFToDocumentinit_parameters:converter:markdown_converter:type: haystack.components.converters.markdown.MarkdownToDocumentinit_parameters:table_to_single_line:falsehtml_converter:type: haystack.components.converters.html.HTMLToDocumentinit_parameters: # A dictionary of keyword arguments to customize how you want to extract content from your HTML files. # For the full list of available arguments, see # the [Trafilatura documentation](https://trafilatura.readthedocs.io/en/latest/corefunctions.html#extract).extraction_kwargs:output_format: txt # Extract text from HTML. You can also also choose "markdown"target_language: # You can define a language (using the ISO 639-1 format) to discard documents that don't match that language.include_tables:true # If true, includes tables in the outputinclude_links:false # If true, keeps links along with their targetsdocx_converter:type: haystack.components.converters.docx.DOCXToDocumentinit_parameters:{}pptx_converter:type: haystack.components.converters.pptx.PPTXToDocumentinit_parameters:{}xlsx_converter:type: deepset_cloud_custom_nodes.converters.xlsx.XLSXToDocumentinit_parameters:{}csv_converter:type: haystack.components.converters.csv.CSVToDocumentinit_parameters:encoding: utf-8joiner:type: haystack.components.joiners.document_joiner.DocumentJoinerinit_parameters:join_mode: concatenatesort_by_score:falsejoiner_xlsx: # merge split documents with non-split xlsx documentstype: haystack.components.joiners.document_joiner.DocumentJoinerinit_parameters:join_mode: concatenatesort_by_score:falsesplitter:type: haystack.components.preprocessors.nltk_document_splitter.NLTKDocumentSplitterinit_parameters:split_by: wordsplit_length:250split_overlap:30respect_sentence_boundary:truelanguage: endocument_embedder:type: deepset_cloud_custom_nodes.embedders.nvidia.document_embedder.DeepsetNvidiaDocumentEmbedderinit_parameters:model: intfloat/e5-base-v2normalize_embeddings:truewriter:type: haystack.components.writers.document_writer.DocumentWriterinit_parameters:document_store:type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStoreinit_parameters:embedding_dim:768policy: OVERWRITEconnections: # Defines how the components are connected-sender: file_classifier.text/plainreceiver: text_converter.sources-sender: file_classifier.application/pdfreceiver: pdf_converter.sources-sender: file_classifier.text/markdownreceiver: markdown_converter.sources-sender: file_classifier.text/htmlreceiver: html_converter.sources-sender: file_classifier.text/csvreceiver: csv_converter.sources-sender: text_converter.documentsreceiver: joiner.documents-sender: pdf_converter.documentsreceiver: joiner.documents-sender: markdown_converter.documentsreceiver: joiner.documents-sender: html_converter.documentsreceiver: joiner.documents-sender: docx_converter.documentsreceiver: joiner.documents-sender: pptx_converter.documentsreceiver: joiner.documents-sender: joiner.documentsreceiver: splitter.documents-sender: splitter.documentsreceiver: joiner_xlsx.documents-sender: xlsx_converter.documentsreceiver: joiner_xlsx.documents-sender: csv_converter.documentsreceiver: joiner_xlsx.documents-sender: joiner_xlsx.documentsreceiver: document_embedder.documents-sender: document_embedder.documentsreceiver: writer.documentsinputs: # Define the inputs for your pipelinefiles:"file_classifier.sources" # This component will receive the files to index as inputmax_runs_per_component:100metadata:{}
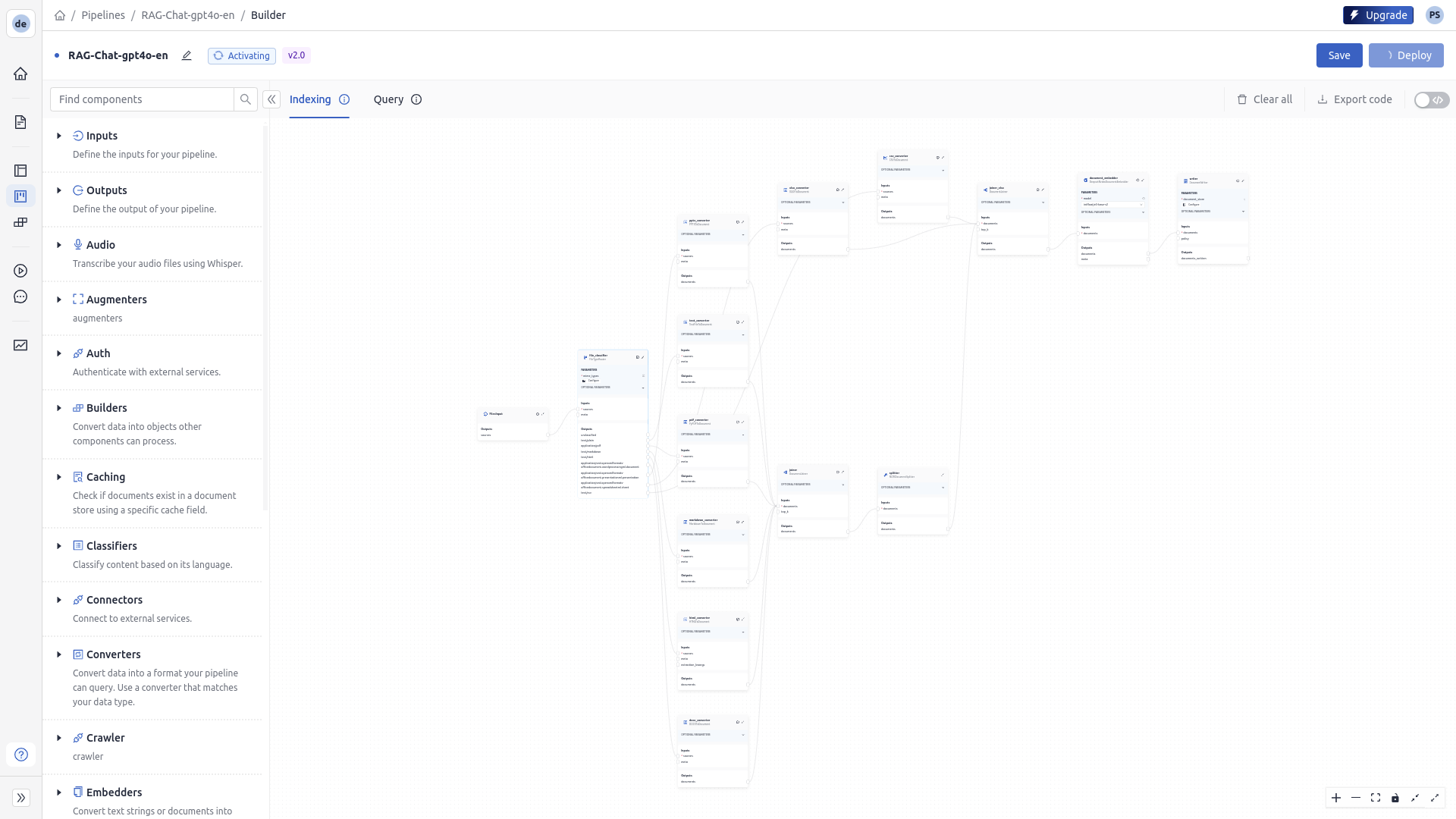
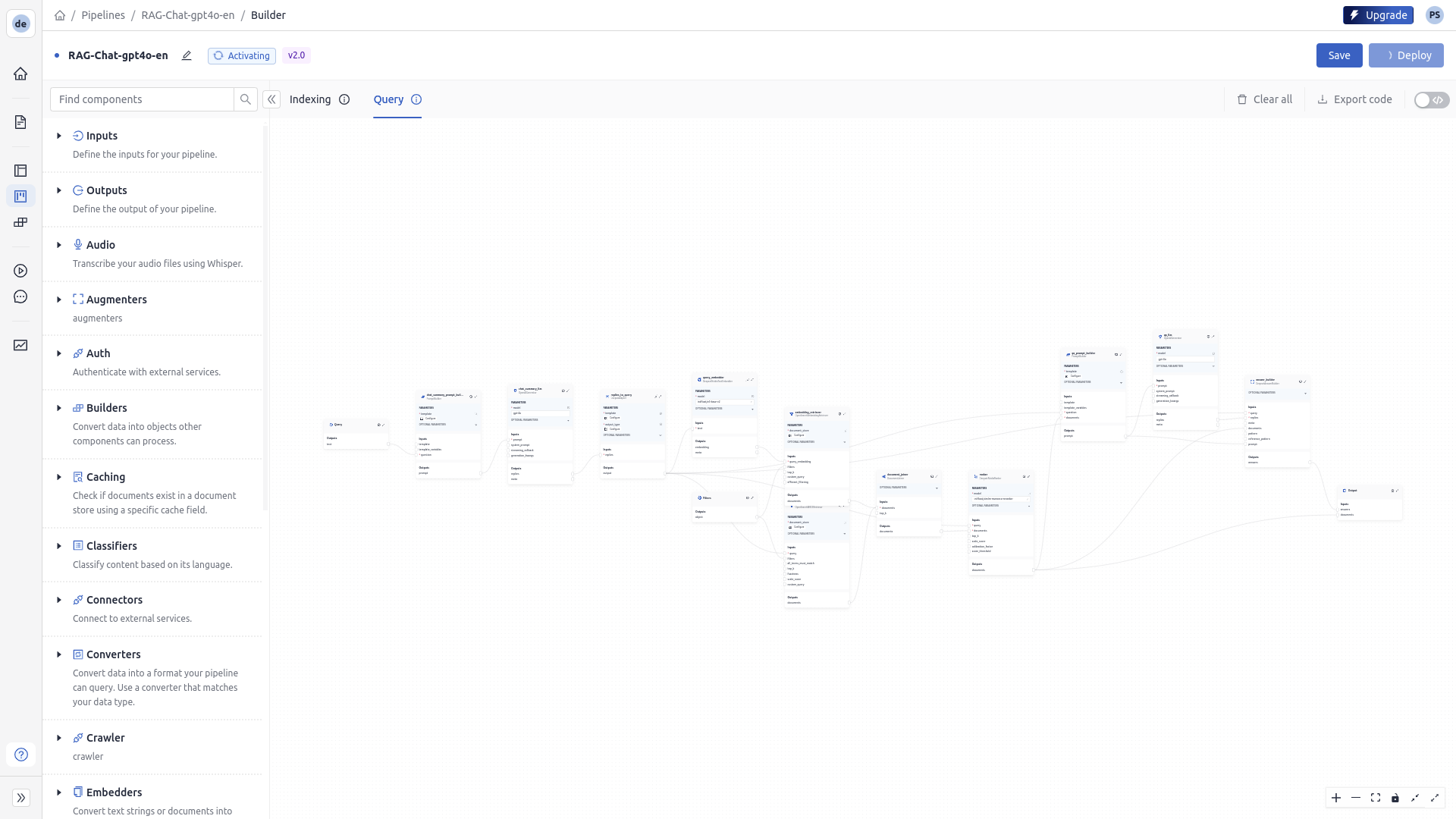
Query Pipeline
image.png
"""# The pipeline contains a component that is only available in deepset Cloud. These components# are optimized to run in a could environment, but you can replace them with the local OSS # version. Check the docs of the component. We provide local examples there. """from haystack import Pipelinefrom haystack.components.builders.prompt_builder import PromptBuilderfrom haystack.utils import Secretfrom haystack.components.generators.openai import OpenAIGeneratorfrom haystack.components.converters.output_adapter import OutputAdapterfrom haystack_integrations.document_stores.opensearch.document_store import OpenSearchDocumentStorefrom haystack_integrations.components.retrievers.opensearch.bm25_retriever import OpenSearchBM25Retrieverfrom deepset_cloud_custom_nodes.embedders.nvidia.text_embedder import DeepsetNvidiaTextEmbedderfrom haystack_integrations.components.retrievers.opensearch.embedding_retriever import OpenSearchEmbeddingRetrieverfrom haystack.components.joiners.document_joiner import DocumentJoinerfrom deepset_cloud_custom_nodes.rankers.nvidia.ranker import DeepsetNvidiaRankerfrom deepset_cloud_custom_nodes.augmenters.deepset_answer_builder import DeepsetAnswerBuilderchat_summary_prompt_builder = PromptBuilder(template="You are part of a chatbot.\nYou receive a question (Current Question) and a chat history.\nUse the context from the chat history and reformulate the question so that it is suitable for retrieval augmented generation.\nIf X is followed by Y, only ask for Y and do not repeat X again.\nIf the question does not require any context from the chat history, output it unedited.\nDon't make questions too long, but short and precise.\nStay as close as possible to the current question.\nOnly output the new question, nothing else!\n\n{{ question }}\n\nNew question:")chat_summary_llm = OpenAIGenerator(api_key=Secret.from_token(["OPENAI_API_KEY"], strict=False), model="gpt-4o", generation_kwargs={"max_tokens": 650, "temperature": 0, "seed": 0})replies_to_query = OutputAdapter(template="{{ replies[0] }}", output_type=str)document_store = OpenSearchDocumentStore(embedding_dim=768)bm25_retriever = OpenSearchBM25Retriever(top_k=20, document_store=document_store)query_embedder = DeepsetNvidiaTextEmbedder(model="intfloat/e5-base-v2", normalize_embeddings=True)document_store = OpenSearchDocumentStore(embedding_dim=768)embedding_retriever = OpenSearchEmbeddingRetriever(top_k=20, document_store=document_store)document_joiner = DocumentJoiner(join_mode="concatenate")ranker = DeepsetNvidiaRanker(model="intfloat/simlm-msmarco-reranker", top_k=8)qa_prompt_builder = PromptBuilder(template="You are a technical expert.\nYou answer questions truthfully based on provided documents.\nIgnore typing errors in the question.\nFor each document check whether it is related to the question.\nOnly use documents that are related to the question to answer it.\nIgnore documents that are not related to the question.\nIf the answer exists in several documents, summarize them.\nOnly answer based on the documents provided. Don't make things up.\nJust output the structured, informative and precise answer and nothing else.\nIf the documents can't answer the question, say so.\nAlways use references in the form [NUMBER OF DOCUMENT] when using information from a document, e.g. [3] for Document[3].\nNever name the documents, only enter a number in square brackets as a reference.\nThe reference must only refer to the number that comes in square brackets after the document.\nOtherwise, do not use brackets in your answer and reference ONLY the number of the document without mentioning the word document.\nThese are the documents:\n{% for document in documents %}\nDocument[{{ loop.index }}]:\n{{ document.content }}\n{% endfor %}\n\nQuestion: {{ question }}\nAnswer:")qa_llm = OpenAIGenerator(api_key=Secret.from_token(["OPENAI_API_KEY"], strict=False), model="gpt-4o", generation_kwargs={"max_tokens": 650, "temperature": 0, "seed": 0})answer_builder = DeepsetAnswerBuilder(reference_pattern="acm")pipeline = Pipeline()pipeline.add_component("chat_summary_prompt_builder", chat_summary_prompt_builder)pipeline.add_component("chat_summary_llm", chat_summary_llm)pipeline.add_component("replies_to_query", replies_to_query)pipeline.add_component("bm25_retriever", bm25_retriever)pipeline.add_component("query_embedder", query_embedder)pipeline.add_component("embedding_retriever", embedding_retriever)pipeline.add_component("document_joiner", document_joiner)pipeline.add_component("ranker", ranker)pipeline.add_component("qa_prompt_builder", qa_prompt_builder)pipeline.add_component("qa_llm", qa_llm)pipeline.add_component("answer_builder", answer_builder)pipeline.connect("chat_summary_prompt_builder.prompt", "chat_summary_llm.prompt")pipeline.connect("chat_summary_llm.replies", "replies_to_query.replies")pipeline.connect("replies_to_query.output", "bm25_retriever.query")pipeline.connect("replies_to_query.output", "query_embedder.text")pipeline.connect("replies_to_query.output", "ranker.query")pipeline.connect("replies_to_query.output", "qa_prompt_builder.question")pipeline.connect("replies_to_query.output", "answer_builder.query")pipeline.connect("bm25_retriever.documents", "document_joiner.documents")pipeline.connect("query_embedder.embedding", "embedding_retriever.query_embedding")pipeline.connect("embedding_retriever.documents", "document_joiner.documents")pipeline.connect("document_joiner.documents", "ranker.documents")pipeline.connect("ranker.documents", "qa_prompt_builder.documents")pipeline.connect("ranker.documents", "answer_builder.documents")pipeline.connect("qa_prompt_builder.prompt", "qa_llm.prompt")pipeline.connect("qa_prompt_builder.prompt", "answer_builder.prompt")pipeline.connect("qa_llm.replies", "answer_builder.replies")# Documentation:# To run the pipeline, use the pipeline.run() method with the appropriate data.# Here is an example on how to execute the pipeline:# The pipeline is defined and loaded above. To execute it, use:result = pipeline.run(data={"chat_summary_prompt_builder":{"question":"..."},"bm25_retriever":{"filters":"..."},"embedding_retriever":{"filters":"..."}})
# If you need help with the YAML format, have a look at https://docs.cloud.deepset.ai/v2.0/docs/create-a-pipeline#create-a-pipeline-using-pipeline-editor.# This section defines components that you want to use in your pipelines. Each component must have a name and a type. You can also set the component's parameters here.# The name is up to you, you can give your component a friendly name. You then use components' names when specifying the connections in the pipeline.# Type is the class path of the component. You can check the type on the component's documentation page.components:chat_summary_prompt_builder:type: haystack.components.builders.prompt_builder.PromptBuilderinit_parameters: template: |- You are part of a chatbot. You receive a question (Current Question) and a chat history. Use the context from the chat history and reformulate the question so that it is suitable for retrieval augmented generation. If X is followed by Y, only ask for Y and do not repeat X again. If the question does not require any context from the chat history, output it unedited. Don't make questions too long, but short and precise. Stay as close as possible to the current question. Only output the new question, nothing else! {{ question }} New question:chat_summary_llm:type: haystack.components.generators.openai.OpenAIGeneratorinit_parameters:api_key:{"type":"env_var","env_vars":["OPENAI_API_KEY"],"strict":False}model:"gpt-4o"generation_kwargs:max_tokens:650temperature:0.0seed:0replies_to_query:type: haystack.components.converters.output_adapter.OutputAdapterinit_parameters:template:"{{ replies[0] }}"output_type: strbm25_retriever: # Selects the most similar documents from the document storetype: haystack_integrations.components.retrievers.opensearch.bm25_retriever.OpenSearchBM25Retrieverinit_parameters:document_store:type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStoreinit_parameters:embedding_dim:768top_k:20 # The number of results to returnquery_embedder:type: deepset_cloud_custom_nodes.embedders.nvidia.text_embedder.DeepsetNvidiaTextEmbedderinit_parameters:model: intfloat/e5-base-v2normalize_embeddings:trueembedding_retriever: # Selects the most similar documents from the document storetype: haystack_integrations.components.retrievers.opensearch.embedding_retriever.OpenSearchEmbeddingRetrieverinit_parameters:document_store:type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStoreinit_parameters:embedding_dim:768top_k:20 # The number of results to returndocument_joiner:type: haystack.components.joiners.document_joiner.DocumentJoinerinit_parameters:join_mode: concatenateranker:type: deepset_cloud_custom_nodes.rankers.nvidia.ranker.DeepsetNvidiaRankerinit_parameters:model: intfloat/simlm-msmarco-rerankertop_k:8qa_prompt_builder:type: haystack.components.builders.prompt_builder.PromptBuilderinit_parameters: template: |- You are a technical expert. You answer questions truthfully based on provided documents. Ignore typing errors in the question. For each document check whether it is related to the question. Only use documents that are related to the question to answer it. Ignore documents that are not related to the question. If the answer exists in several documents, summarize them. Only answer based on the documents provided. Don't make things up. Just output the structured, informative and precise answer and nothing else. If the documents can't answer the question, say so. Always use references in the form [NUMBER OF DOCUMENT] when using information from a document, e.g. [3] for Document[3]. Never name the documents, only enter a number in square brackets as a reference. The reference must only refer to the number that comes in square brackets after the document. Otherwise, do not use brackets in your answer and reference ONLY the number of the document without mentioning the word document. These are the documents: {% for document in documents %} Document[{{ loop.index }}]: {{ document.content }} {% endfor %} Question: {{ question }} Answer:qa_llm:type: haystack.components.generators.openai.OpenAIGeneratorinit_parameters:api_key:{"type":"env_var","env_vars":["OPENAI_API_KEY"],"strict":False}model:"gpt-4o"generation_kwargs:max_tokens:650temperature:0.0seed:0answer_builder:type: deepset_cloud_custom_nodes.augmenters.deepset_answer_builder.DeepsetAnswerBuilderinit_parameters:reference_pattern: acmconnections: # Defines how the components are connected-sender: chat_summary_prompt_builder.promptreceiver: chat_summary_llm.prompt-sender: chat_summary_llm.repliesreceiver: replies_to_query.replies-sender: replies_to_query.outputreceiver: bm25_retriever.query-sender: replies_to_query.outputreceiver: query_embedder.text-sender: replies_to_query.outputreceiver: ranker.query-sender: replies_to_query.outputreceiver: qa_prompt_builder.question-sender: replies_to_query.outputreceiver: answer_builder.query-sender: bm25_retriever.documentsreceiver: document_joiner.documents-sender: query_embedder.embeddingreceiver: embedding_retriever.query_embedding-sender: embedding_retriever.documentsreceiver: document_joiner.documents-sender: document_joiner.documentsreceiver: ranker.documents-sender: ranker.documentsreceiver: qa_prompt_builder.documents-sender: ranker.documentsreceiver: answer_builder.documents-sender: qa_prompt_builder.promptreceiver: qa_llm.prompt-sender: qa_prompt_builder.promptreceiver: answer_builder.prompt-sender: qa_llm.repliesreceiver: answer_builder.repliesinputs: # Define the inputs for your pipelinequery: # These components will receive the query as input-"chat_summary_prompt_builder.question"filters: # These components will receive a potential query filter as input-"bm25_retriever.filters"-"embedding_retriever.filters"outputs: # Defines the output of your pipelinedocuments:"ranker.documents" # The output of the pipeline is the retrieved documentsanswers:"answer_builder.answers" # The output of the pipeline is the generated answers