How many addresses for each street in postcode 3000?
# filter to postcode 3000gnaf_melbourne = gnaf[gnaf['POSTCODE'] ==3000]# count the number of addresses per street in postcode 3000melbourne_street_counts = gnaf_melbourne.groupby('STREET_NAME').size()# sort the data in descending order by the number of addressesmelbourne_street_counts.sort_values(ascending=False)
STREET_NAME
LONSDALE 11138
ABECKETT 10538
COLLINS 10066
LITTLE LONSDALE 9718
LA TROBE 7462
...
RUTLEDGE 1
HEAPE 1
HARWOOD 1
RACING CLUB 1
DOMAIN 1
Length: 165, dtype: int64
STREET_NAME
B 500267
C 467428
M 426049
S 326787
P 299393
W 296203
H 258910
G 250268
A 220864
R 217310
T 213359
L 196466
D 181450
K 167153
F 161510
E 143570
N 121485
O 119007
J 86372
V 68137
I 37394
Y 36899
Q 26382
U 22352
Z 2993
X 123
4 21
Name: count, dtype: int64
/var/folders/7h/4cq59zrd6vb2jqwxh3wdk3nw0000gn/T/ipykernel_2994/1041641723.py:7: DeprecationWarning: `count` is deprecated. It has been renamed to `len`.
.count()
/var/folders/7h/4cq59zrd6vb2jqwxh3wdk3nw0000gn/T/ipykernel_2994/2471861764.py:9: DeprecationWarning: `count` is deprecated. It has been renamed to `len`.
.count()
# column names of 2023 data so that they match the previous yearsfor filename in all_files[-11:]:print(filename) nyc_data = pl.read_parquet(f'{filenames_nyc}/{filename}').rename({'Airport_fee': 'airport_fee'}) nyc_data.write_parquet(f'{filenames_nyc}/{filename}')
# consider only data from 2011 as the format changed# ensure that the columns of all files are the data types# probably not the best way of doing thisfor filename in all_files: nyc_data = pl.scan_parquet(f'{filenames_nyc}/{filename}') nyc_data.select( pl.col('VendorID').cast(pl.Int64), pl.col('tpep_pickup_datetime').cast(pl.Datetime), pl.col('tpep_dropoff_datetime').cast(pl.Datetime), pl.col('passenger_count').cast(pl.Int64), pl.col('trip_distance').cast(pl.Float64), pl.col('RatecodeID').cast(pl.Int64), pl.col('store_and_fwd_flag').cast(pl.String), pl.col('PULocationID').cast(pl.Int64), pl.col('DOLocationID').cast(pl.Int64), pl.col('payment_type').cast(pl.Int64), pl.col('fare_amount').cast(pl.Float64), pl.col('extra').cast(pl.Float64), pl.col('mta_tax').cast(pl.Float64), pl.col('tip_amount').cast(pl.Float64), pl.col('tolls_amount').cast(pl.Float64), pl.col('improvement_surcharge').cast(pl.Float64), pl.col('total_amount').cast(pl.Float64), pl.col('congestion_surcharge').cast(pl.Float64), pl.col('airport_fee').cast(pl.Float64) ).collect().write_parquet(f'{filenames_nyc}/{filename}')
# load the data foldernyc_taxis = pl.scan_parquet(f'{filenames_nyc}/*.parquet')
# how many rows in the data?nyc_taxis.select(pl.len()).collect()
shape: (1, 1)
len
u32
1397171103
# what is the max fare?nyc_taxis.select(pl.max('fare_amount')).collect()
shape: (1, 1)
fare_amount
f64
998310.03
# what is the average fare?nyc_taxis.select(pl.mean('fare_amount')).collect()
shape: (1, 1)
fare_amount
f64
12.433398
# what is the median fare?nyc_taxis.select(pl.median('fare_amount')).collect()
shape: (1, 1)
fare_amount
f64
9.0
# what is the distribution of passenger counts?nyc_taxis.group_by('passenger_count').len().sort('len', descending=True).collect().head(10)
# how many different pickup locations are there?nyc_taxis.group_by('PULocationID').len().collect()
shape: (265, 2)
PULocationID
len
i64
u32
140
23757796
161
50241528
6
6851
146
1590748
30
887
…
…
232
2785351
229
27277422
238
24580042
250
52011
104
201
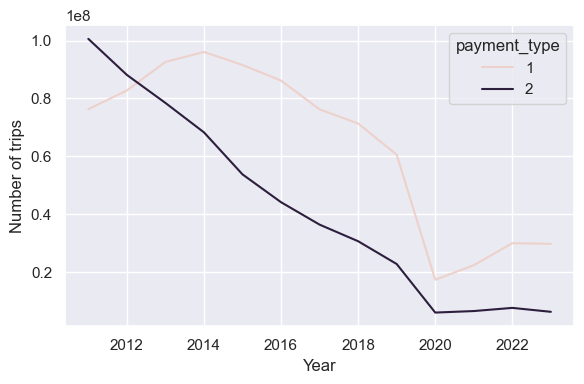
# let's see how people are paying over timepayment_types_year = ( nyc_taxis .with_columns(pl.col('tpep_pickup_datetime').dt.year().alias('pickup_year')) .group_by(pl.col(['pickup_year', 'payment_type'])) .len() .filter(pl.col('pickup_year').is_in(list(range(2011,2024)))) .filter(pl.col('payment_type').is_in([1,2])) .sort(pl.col('pickup_year')) .collect())
plt.figure(figsize=(6, 4))sns.lineplot(data=payment_types_year.to_pandas(), x='pickup_year', y='len', hue='payment_type')plt.xlabel('Year')plt.ylabel('Number of trips')plt.tight_layout()plt.savefig('payments_over_time_nyc_taxis.png')