import warnings
warnings.filterwarnings("ignore")L4: Structured Generation with Outlines
⏳ Note (Kernel Starting): This notebook takes about 30 seconds to be ready to use. You may start and watch the video while you wait.
import outlines
# Downloads the model from HuggingFace if you don't already have it,
# then loads it into memory
model = outlines.models.transformers("HuggingFaceTB/SmolLM2-135M-Instruct")
💻 Access requirements.txt and helper.py files: 1) click on the “File” option on the top menu of the notebook and then 2) click on “Open”.
⬇ Download Notebooks: 1) click on the “File” option on the top menu of the notebook and then 2) click on “Download as” and select “Notebook (.ipynb)”.
📒 For more help, please see the “Appendix – Tips, Help, and Download” Lesson.
from pydantic import BaseModel
class Person(BaseModel):
name: str
age: intfrom utils import track_logits
generator = outlines.generate.json(model, Person, sampler=outlines.samplers.greedy())
# Add tools to track token probabilities as they are generated
track_logits(generator)<outlines.generate.api.SequenceGeneratorAdapter at 0x7f5a875d0110>Chat templating
from utils import template
print(
template(
model,
"Give me a person with a name and an age.",
system_prompt="You create users.",
)
)<|im_start|>system
You create users.<|im_end|>
<|im_start|>user
Give me a person with a name and an age.<|im_end|>
<|im_start|>assistant
# Remove any previously tracked logits
generator.logits_processor.clear()
person = generator(
template(
model,
"Give me a person with a name and an age.",
system_prompt="You create users.",
),
)
personPerson(name='John', age=30)The basic structure
print(person.model_dump_json(indent=4)){
"name": "John",
"age": 30
}from utils import plot_token_distributions
plot_token_distributions(generator.logits_processor, positions=[0], k=5)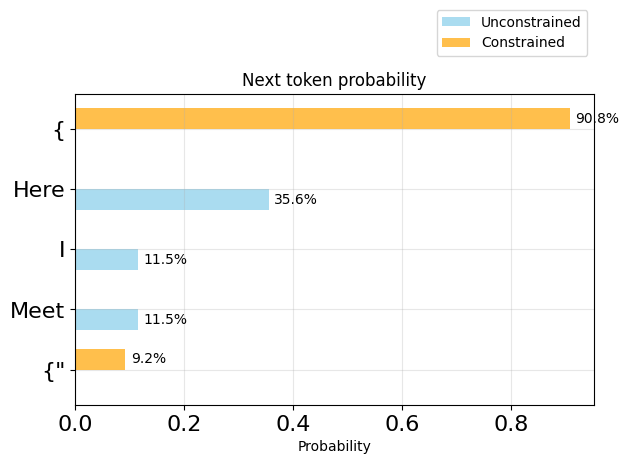
You try!
from utils import plot_token_distributions
plot_token_distributions(generator.logits_processor, positions=[0], k=10)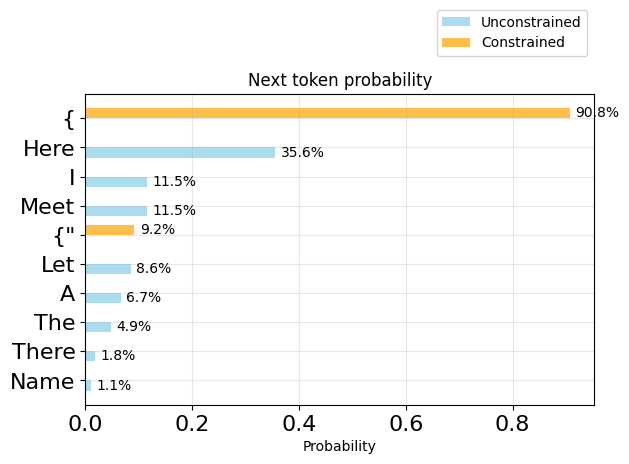
What’s in a name?
plot_token_distributions(generator.logits_processor, positions=[3], k=5)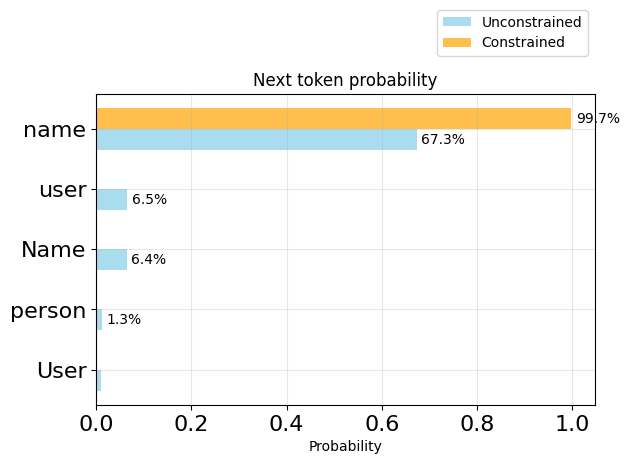
print(generator.logits_processor.sequence(5))
{ "nameplot_token_distributions(generator.logits_processor, positions=[4], k=5)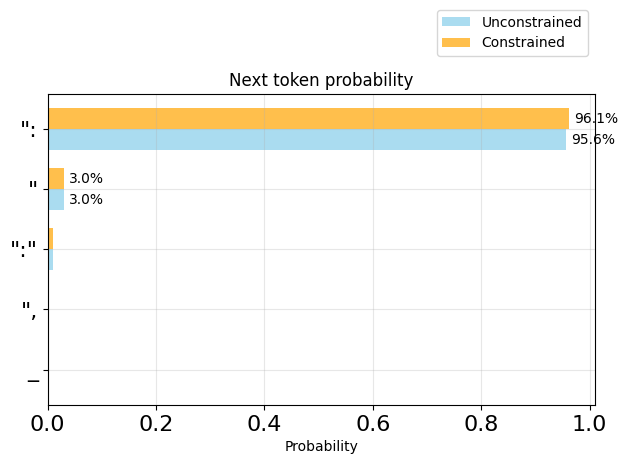
print(generator.logits_processor.sequence(7))
{ "name": "plot_token_distributions(generator.logits_processor, positions=[6], k=5)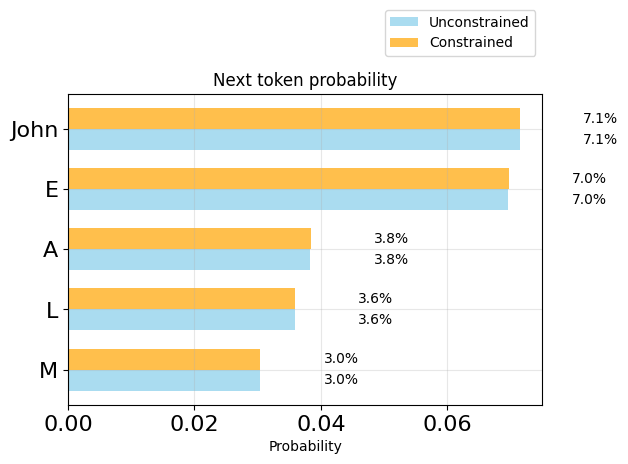
plot_token_distributions(generator.logits_processor, positions=[7], k=5)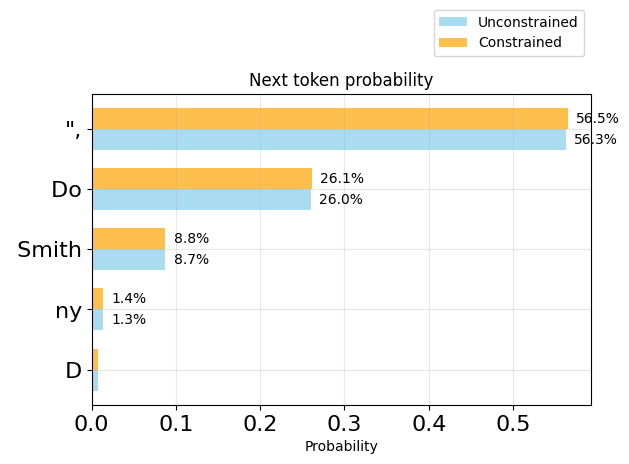
plot_token_distributions(generator.logits_processor, positions=[9, 12], k=5)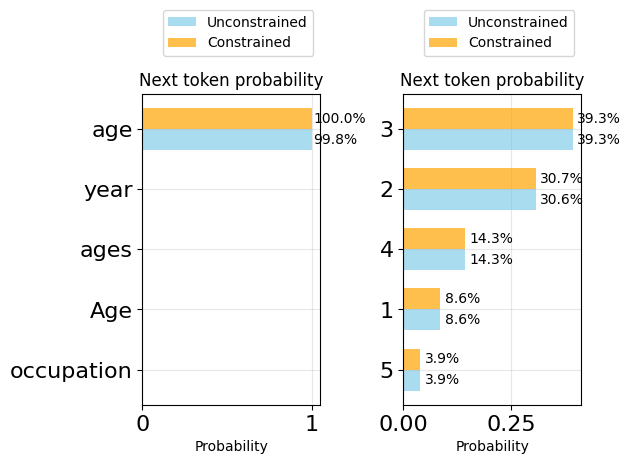
plot_token_distributions(generator.logits_processor, positions=[12, 13], k=5)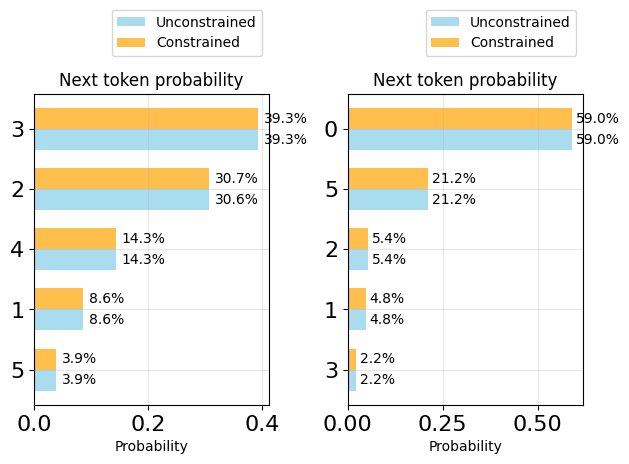
plot_token_distributions(generator.logits_processor, positions=[14, 15], k=5)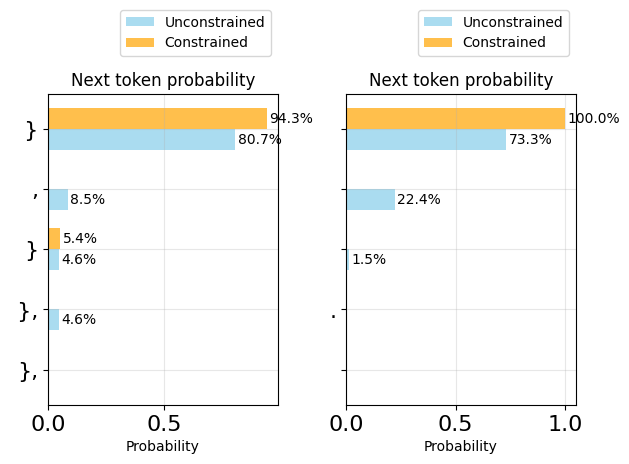
You try!
from typing import Literal
class EmployedPerson(BaseModel):
name: str
age: int
job: Literal["Doctor", "Basketball Player", "Welder", "Dog catcher"]
gen = track_logits(
outlines.generate.json(model, EmployedPerson, sampler=outlines.samplers.greedy())
)
person = gen(template(model, "Give me a person with a name, age, and job."))plot_token_distributions(gen.logits_processor, positions=[20, 21])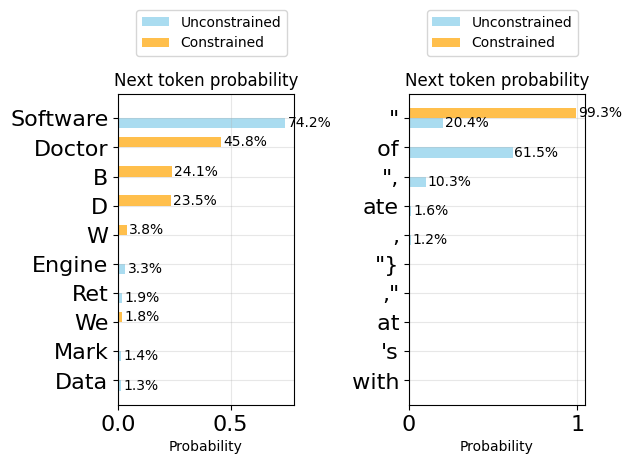
personEmployedPerson(name='John Doe', age=30, job='Doctor')from typing import Literal
class EmployedPerson(BaseModel):
name: str
age: int
job: Literal["Doctor", "Software Engineer", "Artist", "Dancer"]
gen = track_logits(
outlines.generate.json(model, EmployedPerson, sampler=outlines.samplers.greedy())
)
person = gen(template(model, "Give me a person from India, with a name, age, and job."))plot_token_distributions(gen.logits_processor, positions=[20, 21])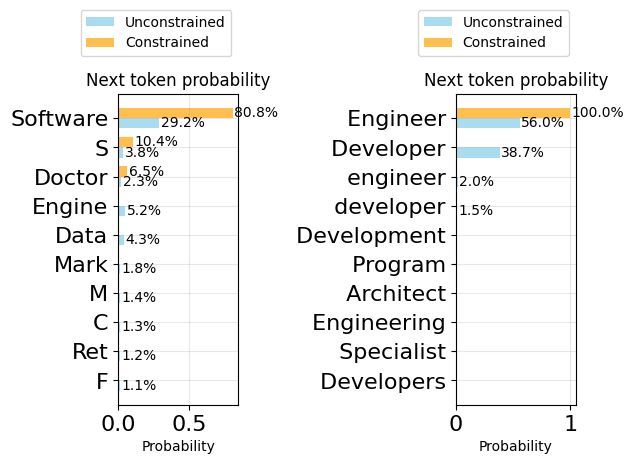
personEmployedPerson(name='Anjali', age=30, job='Software Engineer')