!pip install -q haystack-ai datasets![]()
Advent of Haystack: Day 10
In this challenge, we will evaluate our RAG pipeline using EvaluationHarness, an evaluation orchestrator that streamlines the assessment of pipeline performance, making the evaluation process simpler and more efficient.
🧪 EvaluationHarness is an experimental feature that will be merged into the main repository with Haystack 2.9.0. Find more info in this GitHub discussion
Installation
Start by installing haystack-ai and datasets packages:
Enter OpenAI and HF API Keys
In this challenge, you will use meta-llama/Llama-3.2-1B-Instruct and meta-llama/Llama-3.2-3B-Instruct which are gated and requires extra steps to access through Hugging Face Inference API.
To access these models: 1. You need a Hugging Face account 2. You have to accept conditions in their model pages. You will get access in short time 3. Copy your HF token (https://huggingface.co/settings/tokens) and paste it below
The model page should have “You have been granted access to this model” text to indicate that you can use these models

NOTE: To be able to use LLM-based evaluators, such as FaithfulnessEvaluator, ContextRelevanceEvaluator, you need an OPENAI_API_KEY. Feel free to skip this key if you don’t want to use these metrics.
import os
from getpass import getpass
os.environ["HF_API_TOKEN"] = getpass("Your Hugging Face token")
os.environ["OPENAI_API_KEY"] = getpass("Enter OpenAI API key:")Your Hugging Face token··········
Enter OpenAI API key:··········Prepare the Dataset
Download the HotpotQA dataset from Hugging Face:
from datasets import load_dataset
data = load_dataset(
"hotpotqa/hotpot_qa", "distractor", split="train[:50]", trust_remote_code=True
)/usr/local/lib/python3.10/dist-packages/huggingface_hub/utils/_auth.py:94: UserWarning:
The secret `HF_TOKEN` does not exist in your Colab secrets.
To authenticate with the Hugging Face Hub, create a token in your settings tab (https://huggingface.co/settings/tokens), set it as secret in your Google Colab and restart your session.
You will be able to reuse this secret in all of your notebooks.
Please note that authentication is recommended but still optional to access public models or datasets.
warnings.warn(Check one of the entries to understand the data structure. In Hotpot QA, each entry includes a question, a ground-truth answer, context sentences and titles.
data[4]{'id': '5a84dd955542997b5ce3ff79',
'question': 'Cadmium Chloride is slightly soluble in this chemical, it is also called what?',
'answer': 'alcohol',
'type': 'bridge',
'level': 'medium',
'supporting_facts': {'title': ['Cadmium chloride', 'Ethanol'],
'sent_id': [1, 0]},
'context': {'title': ['Cadmium chloride',
'Water blue',
'Diflucortolone valerate',
'Heptanoic acid',
'Magnesium chloride',
'Ethanol',
'Tributyltin oxide',
'Benzamide',
'Gold(III) chloride',
'Chloride'],
'sentences': [['Cadmium chloride is a white crystalline compound of cadmium and chlorine, with the formula CdCl.',
' It is a hygroscopic solid that is highly soluble in water and slightly soluble in alcohol.',
' Although it is considered to be ionic, it has considerable covalent character to its bonding.',
' The crystal structure of cadmium chloride (described below), composed of two-dimensional layers of ions, is a reference for describing other crystal structures.',
' Also known are CdCl•HO and CdCl•5HO.'],
['Water blue, also known as aniline blue, Acid blue 22, Soluble Blue 3M, Marine Blue V, or C.I. 42755, is a chemical compound used as a stain in histology.',
' Water blue stains collagen blue in tissue sections.',
' It is soluble in water and slightly soluble in ethanol.'],
['Diflucortolone valerate (also "Nerisone" cream/oily cream/ointment, "Neriderm" ointment, Japanese ジフルコルトロン (Jifurucorutoron ) is a corticosteroid rated Class 2 "potent" (100-150 times) in the New Zealand topical steroid system.',
' It is a white to creamy white crystalline powder.',
' It is practically insoluble in water, freely soluble in dichloromethane and in dioxan, sparingly soluble in ether and slightly soluble in methyl alcohol.',
' Chemically, it is a corticosteroid esterified with valeric acid.',
' It is commonly used topically in dermatology.',
' The brand name is Nerisone; its creams come in potencies of 0.1% and 0.3%.'],
['Heptanoic acid, also called enanthic acid, is an organic compound composed of a seven-carbon chain terminating in a carboxylic acid.',
' It is an oily liquid with an unpleasant, rancid odor.',
' It contributes to the odor of some rancid oils.',
' It is slightly soluble in water, but very soluble in ethanol and ether.'],
['Magnesium chloride is the name for the chemical compound with the formula MgCl and its various hydrates MgCl(HO).',
' These salts are typical ionic halides, being highly soluble in water.',
' The hydrated magnesium chloride can be extracted from brine or sea water.',
' In North America, magnesium chloride is produced primarily from Great Salt Lake brine.',
' It is extracted in a similar process from the Dead Sea in the Jordan valley.',
' Magnesium chloride, as the natural mineral bischofite, is also extracted (via solution mining) out of ancient seabeds; for example, the Zechstein seabed in northwest Europe.',
' Some magnesium chloride is made from solar evaporation of seawater.',
' Anhydrous magnesium chloride is the principal precursor to magnesium metal, which is produced on a large scale.',
' Hydrated magnesium chloride is the form most readily available.'],
['Ethanol, also called alcohol, ethyl alcohol, and drinking alcohol, is a compound and simple alcohol with the chemical formula C2H5OH .',
' Its formula can be written also as CH3 −CH2 −OH or C2H5 −OH (an ethyl group linked to a hydroxyl group), and is often abbreviated as EtOH.',
' Ethanol is a volatile, flammable, colorless liquid with a slight characteristic odor.',
' It is used as a drug and is the principal type of alcohol found in alcoholic drinks.'],
['Tributyltin oxide (TBTO) is an organotin compound chiefly used as a biocide (fungicide and molluscicide), especially a wood preservative.',
' Its chemical formula is <ce>[(C4H9)3Sn]2O</ce>.',
' It has the form of a colorless to pale yellow liquid that is only slightly soluble in water (20 ppm) but highly soluble in organic solvents.',
' It is a potent skin irritant.'],
['Benzamide is an off-white solid with the chemical formula of CHCONH.',
' It is a derivative of benzoic acid.',
' It is slightly soluble in water, and soluble in many organic solvents.'],
['Gold(III) chloride, traditionally called auric chloride, is a chemical compound of gold and chlorine.',
' With the molecular formula AuCl, the name gold trichloride is a simplification, referring to the empirical formula, AuCl.',
' The Roman numerals in the name indicate that the gold has an oxidation state of +3, which is common for gold compounds.',
' There is also another related chloride of gold, gold(I) chloride (AuCl).',
' Chloroauric acid, HAuCl, the product formed when gold dissolves in aqua regia, is sometimes referred to as "gold chloride" or "acid gold trichloride".',
' Gold(III) chloride is very hygroscopic and highly soluble in water as well as ethanol.',
' It decomposes above 160\xa0°C or in light.'],
['The chloride ion is the anion (negatively charged ion) Cl.',
' It is formed when the element chlorine (a halogen) gains an electron or when a compound such as hydrogen chloride is dissolved in water or other polar solvents.',
' Chloride salts such as sodium chloride are often very soluble in water.',
' It is an essential electrolyte located in all body fluids responsible for maintaining acid/base balance, transmitting nerve impulses and regulating fluid in and out of cells.',
' Less frequently, the word "chloride" may also form part of the "common" name of chemical compounds in which one or more chlorine atoms are covalently bonded.',
' For example, methyl chloride, with the standard name chloromethane (see IUPAC books) is an organic compound with a covalent C−Cl bond in which the chlorine is not an anion.']]}}Convert the datapoints into Haystack Documents to use in indexing, querying and evaluation. Each sentence will become a Haystack Document and store some information as metadata such as “rank” and “ground_truth_answer”.
from haystack.dataclasses.document import Document
def convert_hotpot_to_docs(data):
question = []
true_answer = []
doc_chunks = []
for item in data:
question.append(item["question"])
true_answer.append(item["answer"])
# Documents
assert len(item["context"]["title"]) == len(item["context"]["sentences"])
context_dict = {
item["context"]["title"][i]: item["context"]["sentences"][i]
for i in range(len(item["context"]["title"]))
}
# Add default rank (irrelevant docs will have the rank of 1000)
for k, v in context_dict.items():
context_dict[k] = [
(vv, 1000, item["id"], item["question"], item["answer"])
for vv in v
if vv.strip()
] # remove empty contents
# Add True rank (irrelevant docs will have the the true rank)
assert len(item["supporting_facts"]["title"]) == len(
item["supporting_facts"]["sent_id"]
)
for i in range(len(item["supporting_facts"]["title"])):
k = item["supporting_facts"]["title"][i] # Key
v_pos = item["supporting_facts"]["sent_id"][1] # Value
rank = i
if v_pos < len(context_dict[k]):
context_dict[k][v_pos] = (
context_dict[k][v_pos][0],
rank,
context_dict[k][v_pos][2],
context_dict[k][v_pos][3],
context_dict[k][v_pos][4],
)
nested_list = [v for k, v in context_dict.items()]
chunks = [x for xs in nested_list for x in xs]
# Sort by rank (for MRR)
sorted_chunks = sorted(chunks, key=lambda tup: tup[1])
# Create Haystack Documents
doc_chunks.append(
[
Document(
content=tup[0],
meta={
"rank": tup[1],
"data_id": tup[2],
"question": tup[3],
"ground_truth_answer": tup[4],
},
)
for tup in sorted_chunks
]
)
return question, true_answer, doc_chunksThe cache for model files in Transformers v4.22.0 has been updated. Migrating your old cache. This is a one-time only operation. You can interrupt this and resume the migration later on by calling `transformers.utils.move_cache()`.questions, ground_truth_answers, doc_chunks = convert_hotpot_to_docs(data)documents = [doc for chunk in doc_chunks for doc in chunk]A relevant document example after processing:
Document(
id=414..ba,
content: "Arthur's Magazine (1844–1846) was an American literary periodical published in Philadelphia in the 1...",
meta: {'rank': 0, 'data_id': '5a87ab905542996e4f3088c1', 'question': "Which magazine was started first Arthur's Magazine or First for Women?", 'ground_truth_answer': "Arthur's Magazine"}
)Create a ground truth dataset
Then, trim the irrelevant documents for the ground_truth_documents dataset
ground_truth_documents = []
for chunk in doc_chunks:
new_list = []
for doc in chunk:
if doc.meta["rank"] < 1000: # if a document is relevant
new_list.append(doc)
ground_truth_documents.append(new_list)Indexing Documents
Create a pipeline and index documents to InMemoryDocumentStore. For document embeddings, use theBAAI/bge-m3 model through HuggingFaceAPIDocumentEmbedder.
⏳ This step might take around 3 minutes
from haystack import Pipeline
from haystack.components.embedders import HuggingFaceAPIDocumentEmbedder
from haystack.components.writers import DocumentWriter
from haystack.document_stores.in_memory import InMemoryDocumentStore
from haystack.document_stores.types import DuplicatePolicy
document_store = InMemoryDocumentStore()
document_embedder = HuggingFaceAPIDocumentEmbedder(
api_type="serverless_inference_api", api_params={"model": "BAAI/bge-m3"}
)
document_writer = DocumentWriter(
document_store=document_store, policy=DuplicatePolicy.SKIP
)
indexing = Pipeline()
indexing.add_component(instance=document_embedder, name="document_embedder")
indexing.add_component(instance=document_writer, name="document_writer")
indexing.connect("document_embedder.documents", "document_writer.documents")
indexing.run({"document_embedder": {"documents": documents}})Calculating embeddings: 100%|██████████| 65/65 [04:48<00:00, 4.43s/it]
WARNING:haystack.document_stores.in_memory.document_store:ID '5777cc6d0bcf6ca28183bf58a82c6aa103fa068c9d206ba71db5e814ebaf00a0' already exists
WARNING:haystack.document_stores.in_memory.document_store:ID '36d860a54390cde995046b4581e3824fe660c632d0a474dd11707f446f12b9be' already exists{'document_writer': {'documents_written': 2064}}RAG Pipeline
Create a basic RAG pipeline using meta-llama/Llama-3.2-1B-Instruct through HuggingFaceAPIGenerator
from haystack import Pipeline
from haystack.components.builders import PromptBuilder
from haystack.components.embedders import HuggingFaceAPITextEmbedder
from haystack.components.retrievers.in_memory import InMemoryEmbeddingRetriever
from haystack.components.generators import HuggingFaceAPIGenerator
generator = HuggingFaceAPIGenerator(
api_type="serverless_inference_api",
api_params={"model": "meta-llama/Llama-3.2-1B-Instruct"},
)
template = """
<|start_header_id|>assistant<|end_header_id|>
Answer the following question based on the given context information only.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{question}}
Answer:
"""
rag_pipeline = Pipeline()
rag_pipeline.add_component(
"query_embedder",
HuggingFaceAPITextEmbedder(
api_type="serverless_inference_api", api_params={"model": "BAAI/bge-m3"}
),
)
rag_pipeline.add_component(
"retriever", InMemoryEmbeddingRetriever(document_store, top_k=3)
)
rag_pipeline.add_component("prompt_builder", PromptBuilder(template=template))
rag_pipeline.add_component("generator", generator)
rag_pipeline.connect("query_embedder", "retriever.query_embedding")
rag_pipeline.connect("retriever", "prompt_builder.documents")
rag_pipeline.connect("prompt_builder", "generator")<haystack.core.pipeline.pipeline.Pipeline object at 0x7f091a7d4d90>
🚅 Components
- query_embedder: HuggingFaceAPITextEmbedder
- retriever: InMemoryEmbeddingRetriever
- prompt_builder: PromptBuilder
- generator: HuggingFaceAPIGenerator
🛤️ Connections
- query_embedder.embedding -> retriever.query_embedding (List[float])
- retriever.documents -> prompt_builder.documents (List[Document])
- prompt_builder.prompt -> generator.prompt (str)Test your pipeline before starting evaluation
question = (
"Cadmium Chloride is slightly soluble in this chemical, it is also called what?"
)
rag_pipeline.run(
{"query_embedder": {"text": question}, "prompt_builder": {"question": question}}
)/usr/local/lib/python3.10/dist-packages/huggingface_hub/inference/_client.py:2245: FutureWarning: `stop_sequences` is a deprecated argument for `text_generation` task and will be removed in version '0.28.0'. Use `stop` instead.
warnings.warn({'generator': {'replies': [' Organic solvent'],
'meta': [{'model': 'meta-llama/Llama-3.2-1B-Instruct',
'finish_reason': 'eos_token',
'usage': {'completion_tokens': 3}}]}}Task: Evaluate the RAG Pipeline with EvaluationHarness
EvaluationHarness executes a pipeline with a given set of inputs and evaluates its outputs with an evaluation pipeline using Haystack’s built-in Evaluators. This means you don’t need to create a separate evaluation pipeline.
RAGEvaluationHarness class, derived from EvaluationHarness, simplifies the evaluation process specifically for RAG pipelines. It comes with a predefined set of evaluation metrics, detailed in the RAGEvaluationMetric enum, and basic RAG architecture examples, listed in the DefaultRAGArchitecture enum.
Your task is to calculate Semantic Answer Similarity, Faithfulness, Context Relevance, Document Recall (Single hit) and Document MRR scores using RAGEvaluationHarness.
# https://docs.haystack.deepset.ai/reference/experimental-evaluation-harness-api
from haystack_experimental.evaluation.harness.rag import (
DefaultRAGArchitecture,
RAGEvaluationHarness,
RAGEvaluationMetric,
RAGEvaluationInput,
)
# Use Semantic Answer Similarity, Faithfulness, Context Relevance, Document Recall (Single hit) and Document MRR
# Feel free to skip the Faithfulness and Context Relevance if you don't have an OPENAI_API_KEY
# HINT: You need questions, ground_truth_answers and ground_truth_document
pipeline_eval_harness = RAGEvaluationHarness(
rag_pipeline=rag_pipeline,
rag_components=DefaultRAGArchitecture.GENERATION_WITH_EMBEDDING_RETRIEVAL,
metrics={
RAGEvaluationMetric.SEMANTIC_ANSWER_SIMILARITY,
RAGEvaluationMetric.FAITHFULNESS,
RAGEvaluationMetric.CONTEXT_RELEVANCE,
RAGEvaluationMetric.DOCUMENT_RECALL_SINGLE_HIT,
RAGEvaluationMetric.DOCUMENT_MRR,
},
)
eval_harness_input = RAGEvaluationInput(
queries=questions,
ground_truth_answers=ground_truth_answers,
ground_truth_documents=ground_truth_documents,
rag_pipeline_inputs={"prompt_builder": {"question": questions}},
)
harness_eval_run = pipeline_eval_harness.run(
inputs=eval_harness_input, run_name="rag_eval"
)Executing RAG pipeline... 0%| | 0/50 [00:00<?, ?it/s]/usr/local/lib/python3.10/dist-packages/huggingface_hub/inference/_client.py:2245: FutureWarning: `stop_sequences` is a deprecated argument for `text_generation` task and will be removed in version '0.28.0'. Use `stop` instead.
warnings.warn(
100%|██████████| 50/50 [00:26<00:00, 1.85it/s]
/usr/local/lib/python3.10/dist-packages/transformers/models/auto/configuration_auto.py:1006: FutureWarning: The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.
warnings.warn(Executing evaluation pipeline.../usr/local/lib/python3.10/dist-packages/sentence_transformers/SentenceTransformer.py:195: FutureWarning: The `use_auth_token` argument is deprecated and will be removed in v4 of SentenceTransformers.
warnings.warn(100%|██████████| 50/50 [00:42<00:00, 1.17it/s]
100%|██████████| 50/50 [00:44<00:00, 1.12it/s]dir(RAGEvaluationMetric)['CONTEXT_RELEVANCE',
'DOCUMENT_MAP',
'DOCUMENT_MRR',
'DOCUMENT_RECALL_MULTI_HIT',
'DOCUMENT_RECALL_SINGLE_HIT',
'FAITHFULNESS',
'SEMANTIC_ANSWER_SIMILARITY',
'__class__',
'__doc__',
'__members__',
'__module__']dir(RAGEvaluationInput)['__annotations__',
'__class__',
'__dataclass_fields__',
'__dataclass_params__',
'__delattr__',
'__dict__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__le__',
'__lt__',
'__match_args__',
'__module__',
'__ne__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__sizeof__',
'__str__',
'__subclasshook__',
'__weakref__',
'ground_truth_answers',
'ground_truth_documents',
'rag_pipeline_inputs']Create a Score Report
Score report calculates the aggregated score for each metric across all questions
# https://docs.haystack.deepset.ai/reference/evaluation-api#evaluationrunresultscore_report
harness_eval_run.results.score_report()| metrics | score | |
|---|---|---|
| 0 | metric_faithfulness | 0.606667 |
| 1 | metric_context_relevance | 0.900000 |
| 2 | metric_sas | 0.507267 |
| 3 | metric_doc_recall_single | 0.760000 |
| 4 | metric_doc_mrr | 0.636667 |
Increase top_k
Override the top_k value of your retriever and compare the results to the original pipeline evaluation results. Don’t forget to create the score report.
💡 Expect to see an increase in “recall”
HINT: Use RAGEvaluationOverrides instead of building a new pipeline from scratch
from haystack_experimental.evaluation.harness.rag import RAGEvaluationOverrides
## Create a RAGEvaluationOverrides to change the top_k value of retriever and make it 10
overrides = RAGEvaluationOverrides(rag_pipeline={"retriever": {"top_k": 10}})
harness_eval_run_topk = pipeline_eval_harness.run(
inputs=eval_harness_input, run_name="topk_10", overrides=overrides
)Executing RAG pipeline... 0%| | 0/50 [00:00<?, ?it/s]/usr/local/lib/python3.10/dist-packages/huggingface_hub/inference/_client.py:2245: FutureWarning: `stop_sequences` is a deprecated argument for `text_generation` task and will be removed in version '0.28.0'. Use `stop` instead.
warnings.warn(
100%|██████████| 50/50 [00:21<00:00, 2.30it/s]Executing evaluation pipeline...100%|██████████| 50/50 [00:59<00:00, 1.20s/it]
100%|██████████| 50/50 [00:56<00:00, 1.12s/it]## Generate a new score report
harness_eval_run_topk.results.score_report()| metrics | score | |
|---|---|---|
| 0 | metric_faithfulness | 0.636667 |
| 1 | metric_context_relevance | 0.940000 |
| 2 | metric_sas | 0.598425 |
| 3 | metric_doc_recall_single | 0.880000 |
| 4 | metric_doc_mrr | 0.654079 |
Change the Generative Model
Override the RAG pipeline, use meta-llama/Llama-3.2-3B-Instruct as the generative model in the RAG pipeline and see if it improves SAS and faithfulness.
## Create a new RAGEvaluationOverrides to change the generative model
# https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct
overrides = RAGEvaluationOverrides(
rag_pipeline={
"generator": {"api_params": {"model": "meta-llama/Llama-3.2-3B-Instruct"}}
}
)
harness_eval_run_3b = pipeline_eval_harness.run(
inputs=eval_harness_input, run_name="llama_3.2_3b", overrides=overrides
)Executing RAG pipeline... 0%| | 0/50 [00:00<?, ?it/s]/usr/local/lib/python3.10/dist-packages/huggingface_hub/inference/_client.py:2245: FutureWarning: `stop_sequences` is a deprecated argument for `text_generation` task and will be removed in version '0.28.0'. Use `stop` instead.
warnings.warn(
100%|██████████| 50/50 [00:22<00:00, 2.21it/s]Executing evaluation pipeline...100%|██████████| 50/50 [00:49<00:00, 1.01it/s]
100%|██████████| 50/50 [00:38<00:00, 1.30it/s]## Generate a new score report
harness_eval_run_3b.results.score_report()| metrics | score | |
|---|---|---|
| 0 | metric_faithfulness | 0.633333 |
| 1 | metric_context_relevance | 0.880000 |
| 2 | metric_sas | 0.602177 |
| 3 | metric_doc_recall_single | 0.760000 |
| 4 | metric_doc_mrr | 0.636667 |
⭐️ Bonus: Evaluate a Hybrid Retrieval Pipeline ⭐️
Add InMemoryBM25Retriever and DocumentJoiner to create a hybrid retrieval pipeline.
from haystack import Pipeline
from haystack.components.builders import PromptBuilder
from haystack.components.embedders import HuggingFaceAPITextEmbedder
from haystack.components.retrievers.in_memory import (
InMemoryEmbeddingRetriever,
InMemoryBM25Retriever,
)
from haystack.components.generators import HuggingFaceAPIGenerator
from haystack.components.joiners import DocumentJoiner
generator = HuggingFaceAPIGenerator(
api_type="serverless_inference_api",
api_params={"model": "meta-llama/Llama-3.2-1B-Instruct"},
)
template = """
<|start_header_id|>assistant<|end_header_id|>
Answer the following question based on the given context information only.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{question}}
Answer:
"""
hybrid_pipeline = Pipeline()
hybrid_pipeline.add_component(
"query_embedder",
HuggingFaceAPITextEmbedder(
api_type="serverless_inference_api", api_params={"model": "BAAI/bge-m3"}
),
)
hybrid_pipeline.add_component(
"embedding_retriever", InMemoryEmbeddingRetriever(document_store, top_k=3)
)
hybrid_pipeline.add_component(
"bm25_retriever", InMemoryBM25Retriever(document_store, top_k=3)
)
hybrid_pipeline.add_component("joiner", DocumentJoiner())
hybrid_pipeline.add_component("prompt_builder", PromptBuilder(template=template))
hybrid_pipeline.add_component("generator", generator)
hybrid_pipeline.connect("query_embedder", "embedding_retriever.query_embedding")
hybrid_pipeline.connect("embedding_retriever", "joiner")
hybrid_pipeline.connect("bm25_retriever", "joiner")
hybrid_pipeline.connect("joiner", "prompt_builder.documents")
hybrid_pipeline.connect("prompt_builder", "generator")<haystack.core.pipeline.pipeline.Pipeline object at 0x7f082fdd55a0>
🚅 Components
- query_embedder: HuggingFaceAPITextEmbedder
- embedding_retriever: InMemoryEmbeddingRetriever
- bm25_retriever: InMemoryBM25Retriever
- joiner: DocumentJoiner
- prompt_builder: PromptBuilder
- generator: HuggingFaceAPIGenerator
🛤️ Connections
- query_embedder.embedding -> embedding_retriever.query_embedding (List[float])
- embedding_retriever.documents -> joiner.documents (List[Document])
- bm25_retriever.documents -> joiner.documents (List[Document])
- joiner.documents -> prompt_builder.documents (List[Document])
- prompt_builder.prompt -> generator.prompt (str)hybrid_pipeline.show()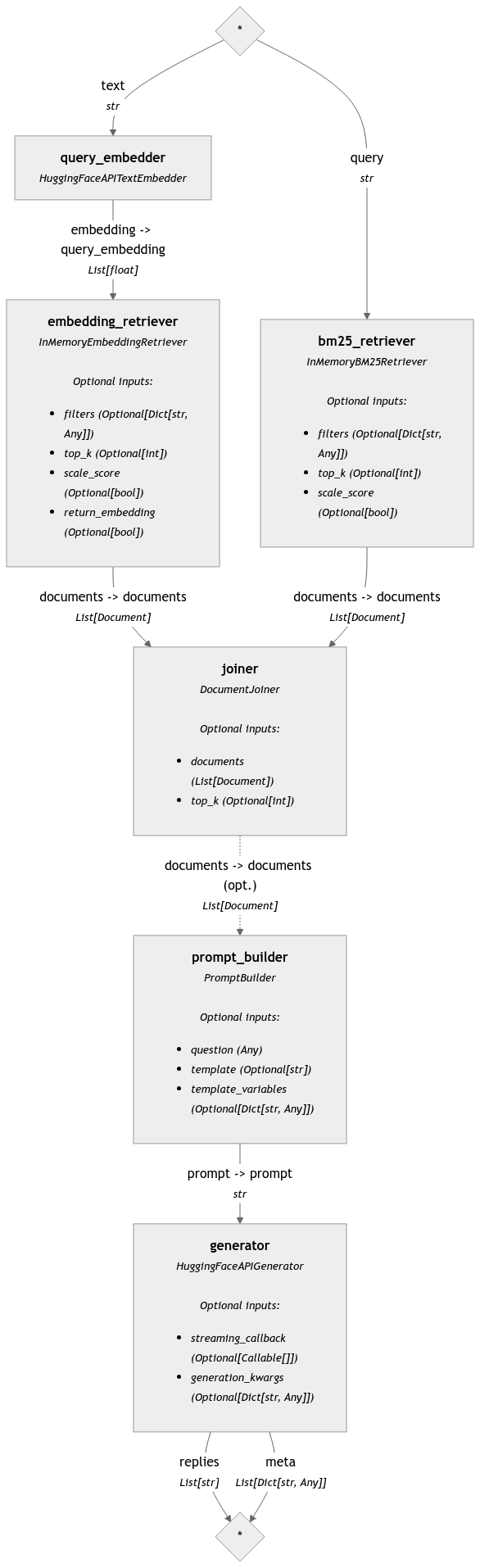
Test the pipeline
question = (
"Cadmium Chloride is slightly soluble in this chemical, it is also called what?"
)
hybrid_pipeline.run(
{
"query_embedder": {"text": question},
"bm25_retriever": {"query": question},
"prompt_builder": {"question": question},
}
)/usr/local/lib/python3.10/dist-packages/huggingface_hub/inference/_client.py:2245: FutureWarning: `stop_sequences` is a deprecated argument for `text_generation` task and will be removed in version '0.28.0'. Use `stop` instead.
warnings.warn({'generator': {'replies': [' Cadmium chloride is slightly soluble in water, but very soluble in ethanol and ether.'],
'meta': [{'model': 'meta-llama/Llama-3.2-1B-Instruct',
'finish_reason': 'eos_token',
'usage': {'completion_tokens': 18}}]}}RAGEvaluationHarness for Custom Pipelines
For RAGEvaluationHarness to work correctly for this custom pipeline, you need to map components correctly using RAGExpectedComponent and RAGExpectedComponentMetadata.
You can find more details in Evaluating RAG Pipelines with EvaluationHarness
# https://docs.haystack.deepset.ai/reference/experimental-evaluation-harness-api#ragexpectedcomponent
from haystack_experimental.evaluation.harness.rag import (
RAGEvaluationHarness,
RAGEvaluationMetric,
RAGEvaluationInput,
RAGExpectedComponent,
RAGExpectedComponentMetadata,
)
# Create a new RAGEvaluationHarness with custom mapping
# Use the same metrics you have used in the first evaluation
# rag_components: expected comp to expected comp metadata mapping
hybrid_eval_harness = RAGEvaluationHarness(
rag_pipeline=hybrid_pipeline,
rag_components={
RAGExpectedComponent.QUERY_PROCESSOR: RAGExpectedComponentMetadata(
name="query_embedder", input_mapping={"query": "text"}
),
RAGExpectedComponent.QUERY_PROCESSOR: RAGExpectedComponentMetadata(
name="bm25_retriever", input_mapping={"query": "query"}
),
RAGExpectedComponent.DOCUMENT_RETRIEVER: RAGExpectedComponentMetadata(
name="joiner", output_mapping={"retrieved_documents": "documents"}
),
RAGExpectedComponent.RESPONSE_GENERATOR: RAGExpectedComponentMetadata(
name="generator", output_mapping={"replies": "replies"}
),
},
metrics={
RAGEvaluationMetric.SEMANTIC_ANSWER_SIMILARITY,
RAGEvaluationMetric.FAITHFULNESS,
RAGEvaluationMetric.CONTEXT_RELEVANCE,
RAGEvaluationMetric.DOCUMENT_RECALL_SINGLE_HIT,
RAGEvaluationMetric.DOCUMENT_MRR,
},
)
eval_harness_input = RAGEvaluationInput(
queries=questions,
ground_truth_answers=ground_truth_answers,
ground_truth_documents=ground_truth_documents,
rag_pipeline_inputs={
"query_embedder": {"text": questions},
"prompt_builder": {"question": questions},
},
)
harness_hybrid_eval_run = hybrid_eval_harness.run(
inputs=eval_harness_input, run_name="rag_eval_hybrid"
)Executing RAG pipeline... 0%| | 0/50 [00:00<?, ?it/s]/usr/local/lib/python3.10/dist-packages/huggingface_hub/inference/_client.py:2245: FutureWarning: `stop_sequences` is a deprecated argument for `text_generation` task and will be removed in version '0.28.0'. Use `stop` instead.
warnings.warn(
100%|██████████| 50/50 [00:23<00:00, 2.10it/s]
/usr/local/lib/python3.10/dist-packages/transformers/models/auto/configuration_auto.py:1006: FutureWarning: The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.
warnings.warn(Executing evaluation pipeline.../usr/local/lib/python3.10/dist-packages/sentence_transformers/SentenceTransformer.py:195: FutureWarning: The `use_auth_token` argument is deprecated and will be removed in v4 of SentenceTransformers.
warnings.warn(
100%|██████████| 50/50 [00:56<00:00, 1.13s/it]
100%|██████████| 50/50 [00:47<00:00, 1.04it/s]dir(RAGExpectedComponent)['DOCUMENT_RETRIEVER',
'QUERY_PROCESSOR',
'RESPONSE_GENERATOR',
'__class__',
'__doc__',
'__members__',
'__module__']## Generate a new score report to see the difference
harness_hybrid_eval_run.results.score_report()| metrics | score | |
|---|---|---|
| 0 | metric_faithfulness | 0.674167 |
| 1 | metric_context_relevance | 0.940000 |
| 2 | metric_sas | 0.533664 |
| 3 | metric_doc_recall_single | 0.840000 |
| 4 | metric_doc_mrr | 0.597667 |